
Sentiment Analysis on Movie Reviews

Description of the Project from Kaggle
The Rotten Tomatoes movie review dataset is a corpus of movie reviews used for sentiment analysis, originally collected by Pang and Lee. In their work on sentiment treebanks, Socher et al. used Amazon’s Mechanical Turk to create fine-grained labels for all parsed phrases in the corpus. This competition presents a chance to benchmark your sentiment-analysis ideas on the Rotten Tomatoes dataset. You are asked to label phrases on a scale of five values: negative, somewhat negative, neutral, somewhat positive, positive. Obstacles like sentence negation, sarcasm, terseness, language ambiguity, and many others make this task very challenging.
Exploratory Data Analysis (EDA)
150K+ movie reviews are in the train dataset and this will be used to train the model to predict the sentiment of test dataset which has 66K+ movie reviews. Before jumping into the modeling, let’s understand the data better.
1. How does the Data Look Like? Phrase is a text and so we could remove characters and grammar words that are not helpful to predict the sentiment. We will also drop PharaseId and SentenceId as they are meaningless numberings when it comes to sentiment in this train dataset.

2. How Common Each Sentiment Appears in the Data 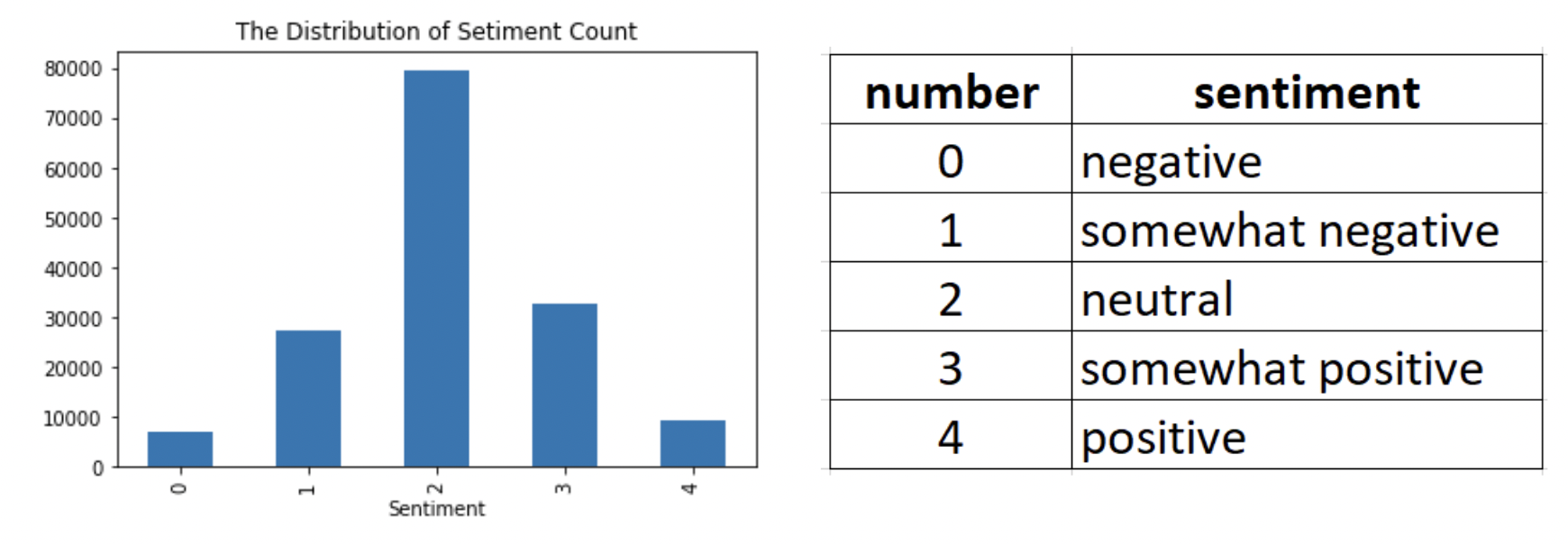
More than 50% of the train data has neutral sentiment, while less than 5% of train data has negative sentiment. This is a 5 class classification problem. Since the data is a chunk text where the order of the word is important, we will implement Long Short Term Memory(LSTM) network to classify these reviews.
Method Used: Long Short Term Memory (LSTM) LSTM is one of Recurrent Neural Networks that is used a lot in sequencing predictions because it does a good job at remembering important previous sequences.
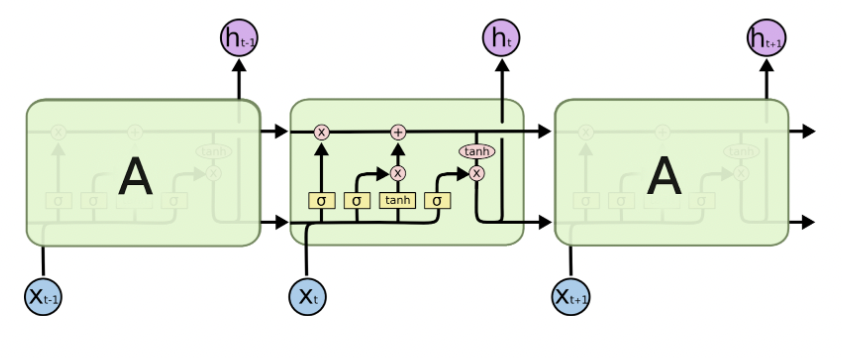
In sentiment analysis, we would like to consider the long context of the reviews together. LSTM can carry information from different timestamps using its memory cell. Thus, it can take the reviews and predict its sentiment better.
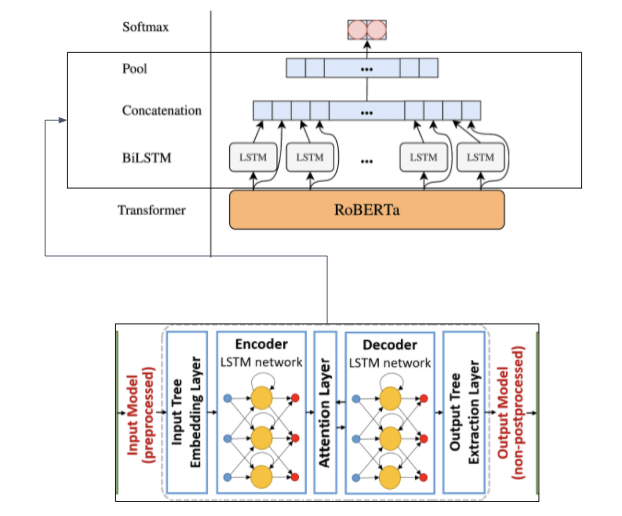
Figure 1: roBERTa encoder to preprocess text; LSTM model to output sentiment classification.
roBERTa is a robustly optimized method for pretraining natural language processing (NLP) systems that improves on Bidirectional Encoder Representations from Transformers, or BERT, the self-supervised method released by Google in 2018. RoBERTa builds on BERT’s language masking strategy, wherein the system learns to predict intentionally hidden sections of text within otherwise unannotated language examples. RoBERTa, which was implemented in PyTorch, modifies key hyperparameters in BERT, including removing BERT’s next-sentence pretraining objective, and training with much larger mini-batches and learning rates. This allows RoBERTa to improve on the masked language modeling objective compared with BERT and leads to better downstream task performance.
Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture. Relative insensitivity to gap length is an advantage of LSTM over other typical RNNs.
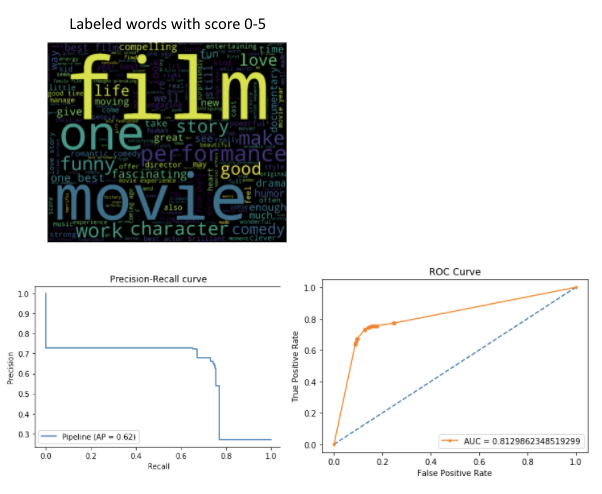
The precision and recall curve is used to determine which threshold to use for classifying sentiments. This curve is obtained by grouping sentiments into negative and positive.
The ROC curve is used to visually check how well the model performs. A larger area under the curve indicates a better model performance.
Figure 2: Model evaluation
The model is evaluated on classification accuracy (the percent of labels that are predicted correctly) for every parsed phrase. The sentiment labels are:
What does it do?
The model determines the sentimental value of movie reviews from Rotten Tomatoes from the written comments from users.
How do I evaluate the project’s success?
We can evaluate how accurate the sentiment values are from the movie reviews that the user has posted online. We can also check other accuracy metrics such as ROC curve.
What did I learn from this project?
I learned how open-ended such movie reviews are and the diversity between the tone and the meanings behind each movie review. Being able to truly interpret a review is important before one watches a movie due to possible underlying messages behind it. So having a model that confirms the sentiment of a review is beneficial. I learned that the pre-processing can be a bit and tedious but is very necessary. For example, the stopwords such as “the”, “are” or “an”, don’t have sentiments attached to it, but they are there for grammatical reason. Thus, it helps to remove those words before training the model as they will only become noise to the model.
What’s next for this project?
Moving from movie reviews to other forms of reviews like restaurants, tourist attractions, malls, etc. can also help people who never had experience be able to truly know if it is worth their time to visit a place.